Le service couvre un périmètre incluant bio-informatique structurale, chemo-informatique, modélisations (moléculaire, données, processus) et informatique scientifique (scientific computing). Actuellement l'activité du service est focalisée sur les aspects in silico liés aux processus de développement de nouvelles molécules (drug design).
Le service fonctionne en mode R&D avec une partie prestation en calcul et visualisation (soutien aux projets de recherche, collaborations) et une partie développement informatique (codes, matériels, données) et méthodologique (CAO moléculaire, algorithmes, intégration de méthodes).
Dans ce contexte, la puissance instrumentale (stations de travail, clusters, GPU) n’est pas au centre du dispositif. La compétitivité est, avant tout, liée aux développements internes (preuves de concept) initiées en amont de la demande et à la connaissance de l’écosystème scientifique.
Prestations
Les prestations incluent l’analyse structurale, la maintenance de bases de connaissances, la production de visualisations complexes, la modélisation (en particulier arrimage moléculaire) et des livrables sous la forme de rapports. Une partie de ce travail est facturable (notamment études de faisabilité, analyses structurales ou visualisation) mais le coût (prix public) d’une modélisation (calculs ou criblage) serait trop élevé pour une unité de recherche. Le financement se fait donc essentiellement sur partage des risques par intégration dans les réponses aux appels d’offres (partenariat).
Modélisation moléculaire et drug-design
Une offre de service modélisation et visualisation moléculaires, a toujours existé au laboratoire, mais depuis 2003 elle a évolué vers un service d'informatique scientifique à l'interface informatique-chimie-biologie. Le catalogue de services couvre donc une partie des méthodes in silico applicables à la conception de molécules d'intérêt biologique: inhibiteurs, sondes moléculaires … dans un contexte structure-based drug design : biologie structurale, modélisations et arrimage moléculaire (docking), CAO moléculaire. Ce catalogue évolue avec la classification (topologie, réseaux d'interactions) de protéines, des protocoles d'arrimage avancés (multimodaux et consensus), la mise au point de métriques (in silico drug efficiencies) et l'intégration de méthodes chemo-informatique (ligand-based drug design) dans les processus de conception.
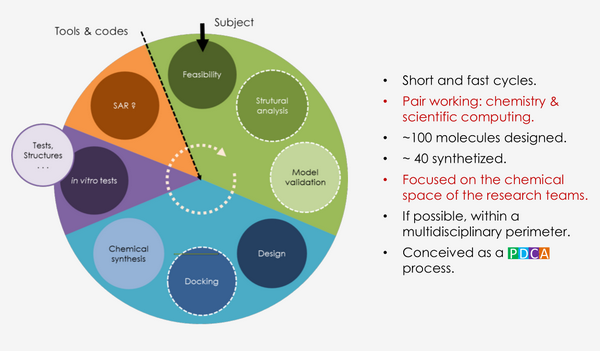
Modeler@lab
Le service peut être projeté temporairement (0,5 à 3 jours avec un matériel adapté) au sein d'un autre laboratoire. L'objectif est d'être au plus près de biologistes ou de cliniciens de manière à faciliter l'hybridation entre une thématique et un approche pratiquée au sein du service, éventuellement la possibilité de collaborations futures avec nos chimistes. Possibilités : évaluation de la faisabilité par rapport à une question scientifique, mise en place de collaborations, action de micro formation in situ.
Modélisation de processus et modélisation de données
Une expertise est également proposée dans des domaines tels que la modélisation de processus (enzymologie au sens large) ou les collections numériques (données, connaissances, molécules) au sens large. Il s'agit d'outils et de méthodes indispensables et positionnés à la frontière des processus de conception. Ils nous permettent, soit de maîtriser l'ensemble de la chaine de conception, soit d'être efficaces lorsque des approches traditionnelles (par exemple un SGBDR) ne sont pas pertinentes. Les notions de généricité, d'agilité, de frugalité des codes, sont au centre de ces approches. Il s'agit de produire des preuves de concept à partir de questions scientifiques issues de communautés scientifiques (chimie-biologie, SHS, sciences de l'environnement ...) élargies et centrées sur les données (data centric).
Contact
frederic.rodriguez@univ-tlse3.fr
ResearchGate

BuildBlog

Plus...
De l'ordre d'une trentaine de types moléculaires ont été couverts, notamment : ADNs modifiés, enzymes de la glycolyse, enzyme et transporteurs liés au métabolisme ou à la signalisation lipidique, superoxide dismutase, anhydrase carbonique, protéines senseurs (chekpoint kinases), protéines liées aux mécanismes épigénétiques, serpines, récepteurs nucléaires liés à des problématiques de cancers, enzymes impliquées dans les voies de synthèse des acydes mycoliques (tuberculose), dans la réparation de l'ADN, indoleamine dioxygenase, hydroxysteroid dehydrogenase, nitric oxide synthase ...